

En días en los que la Inteligencia Artificial Generativa está tan de moda, es necesario conocer a uno de los grandes protagonistas de esta revolución del contenido automático: los modelos de difusión.
Si alguna vez se ha preguntado de dónde viene el nombre de la plataforma generadora de imágenes a partir de texto, Stable Diffusion, le tenemos la respuesta: viene de los modelos de difusión. Más exactamente, del conocido como Latent Diffusion Model.
Y no es la única plataforma que usa esta tecnología. También la utilizan DALL-E, Midjourney o Imagen. Es el siguiente gran paso tras las redes neuronales adversas (GAN). Pero primero, recordemos en qué consiste un modelo de difusión.
En física, se trata de un proceso irreversible que consiste en el desplazamiento de las moléculas de una sustancia de una zona de mayor concentración a otra. Imaginen, por ejemplo, tener un vaso de agua donde se arroja una gota de tinta. Esta gota se irá diluyendo en el agua, mezclándose, y a medida que se arrojen más gotas, estas irán tiñendo totalmente el vaso.
Los modelos de difusión buscan precisamente que, a partir de ese vaso de agua totalmente mezclado, volvamos al punto original cuando la primera gota estaba sin diluir. ¿Suena imposible? Tal vez en el mundo real, pero no en el terreno digital.
¿Cómo funciona en plataformas de Inteligencia Artificial?
Cuando trasladamos el concepto de modelos de difusión al terreno informático, suena simple: se basa en añadir ruido a una imagen hasta difuminarla completamente y luego ser capaces de revertir este proceso. Es decir, partir de un bosquejo lleno de ruido hasta llegar a una imagen reconocible.
Para hacerlo, se utilizan dos partes: la difusión directa y la difusión inversa. En la primera, se añaden, paso a paso, elementos que van distorsionando los datos (en este caso, una imagen), mientras que en la segunda se parte precisamente de unos datos distorsionados, utilizando una red neuronal entrenada, hasta llegar a una serie de imágenes.

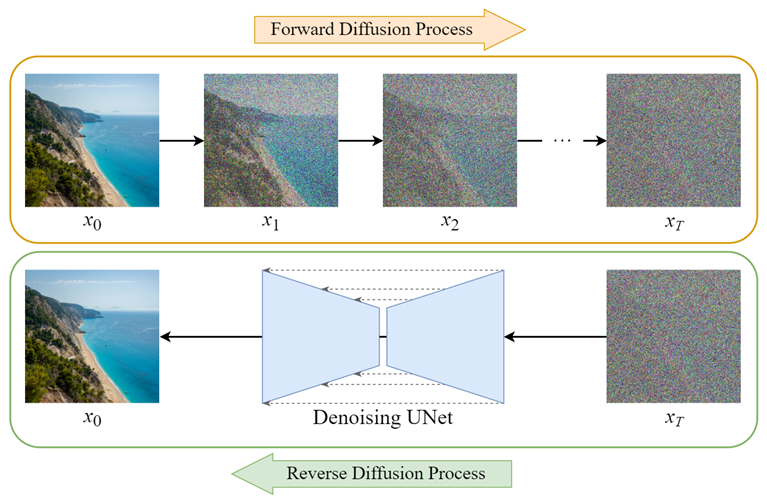
Imagen tomada: https://miro.medium.com/v2/resize:fit:1400/1*xc2Y6jwIUhfEGxJLytU1RA.png
{kind=link}
Para entrenar a esta red neuronal, se le entrega un gran conjunto de imágenes a las cuales se les irá añadiendo distorsiones aleatorias (ruido gaussiano, para ser más exactos), hasta que la máquina aprenda cómo difuminarlas por sí misma.
Esto creará una red potente, pero con algunas limitaciones prácticas, como la lentitud en el procesamiento. Para solucionar este inconveniente, se usa una variación de los modelos de difusión llamada Latent Diffusion Model (LDM). Esta variante, en esencia, segmenta las imágenes volviéndolas más pequeñas al momento de procesarlas, y luego las devuelve a un tamaño mayor al entregar los resultados.
Ahora, la pregunta es: ¿cómo se interactúa con estas plataformas de difusión de imágenes a través de texto? La respuesta viene dada en una sigla: CLIP, o Contrastive Language-Image Pre-Training.
CLIP también es una red neuronal entrenada mediante pares (imagen, texto) desarrollada en 2021 por Open AI, la misma creadora de ChatGPT. Por supuesto, CLIP no es la única plataforma de su tipo, pero es la más conocida y potente tras ser entrenada usando más de 400 millones de imágenes.
Por último, es bueno recordar que los modelos de difusión no solo sirven para crear imágenes, también para eliminar el ruido, mejorar la resolución, generar vídeos de alta calidad, incluso tiene aplicaciones en medicina y mercadeo, pero esa, es otra historia.
Si quieres saber cómo desde Movistar Empresas te podemos ayudar a impulsar la transformación de tu negocio ingresa aquí.
Foto de sketchepedia